Hadoop完全分布式
Hadoop完全分布式
urcuteimmehingeHadoop的三种模式
三种模式:本地 、伪分布式、全分布式、高可用HA(重点)
思考:伪分布式模式存在的问题?
模拟集群 实质上在一个节点上面的操作
全分布式:NN DN SNN 用多台节点(服务器)来运行的,并没有用高可用HA
高可用:HA
集群拓扑
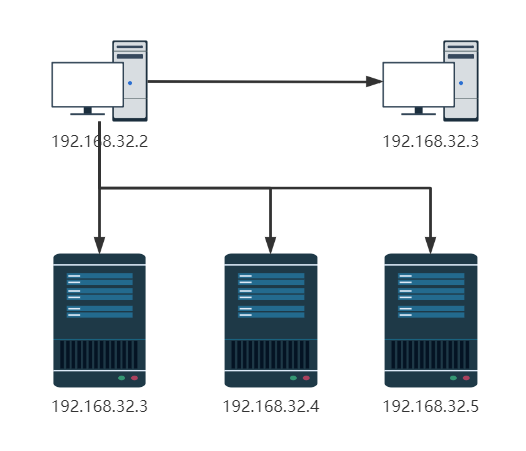
主机(角色)规划
| 节点名称 | IP | namenode | datanode | SecondaryNameNode | 节点类型 |
|---|---|---|---|---|---|
| node01 | 192.168.32.2 | * | * | master | |
| node02 | 192.168.32.3 | * | * | slave | |
| node03 | 192.168.32.4 | * | slave |
准备三个虚拟机,三个虚拟机分别设置好对应的网络ip配置
软件规划
| 软件 | 版本 | 节点 | 说明 |
|---|---|---|---|
| VMware | 16Pro | VM虚拟机 | |
| CentOS | 7 | * | Linux操作系统 |
| JDK | 1.8 | * | Hadoop基于Java,所以必须提前安装JDK |
| Hadoop | 2.7 | * | 存储、运行处理大数据的软件平台 |
软件目录规划
| 目录 | 路径 |
|---|---|
| 所有软件包存放目录 | /usr/tools/ |
| 大数据软件安装目录 | /usr/local/ |
虚拟机安装
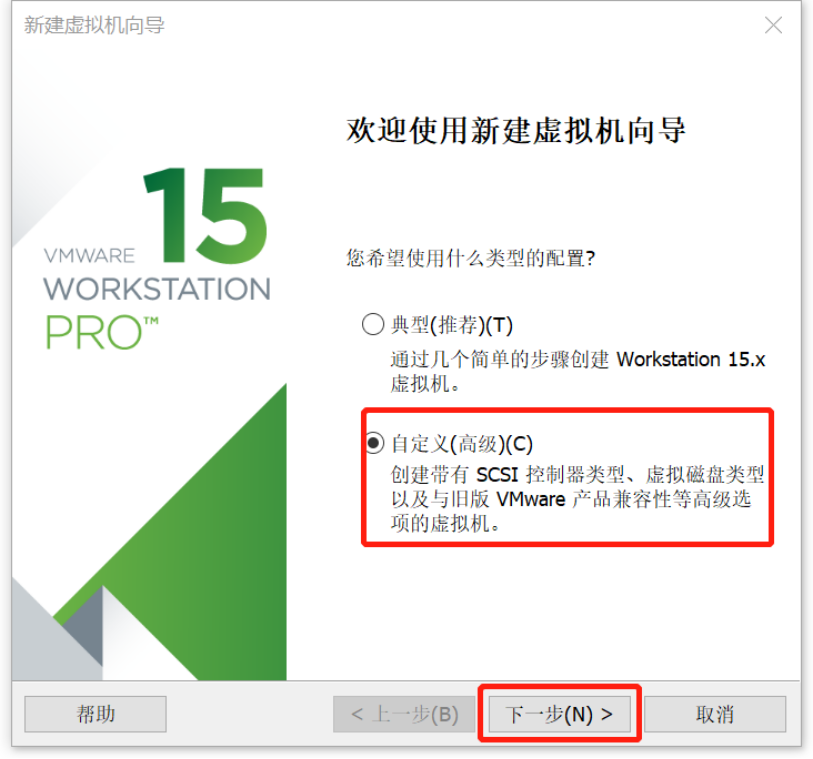
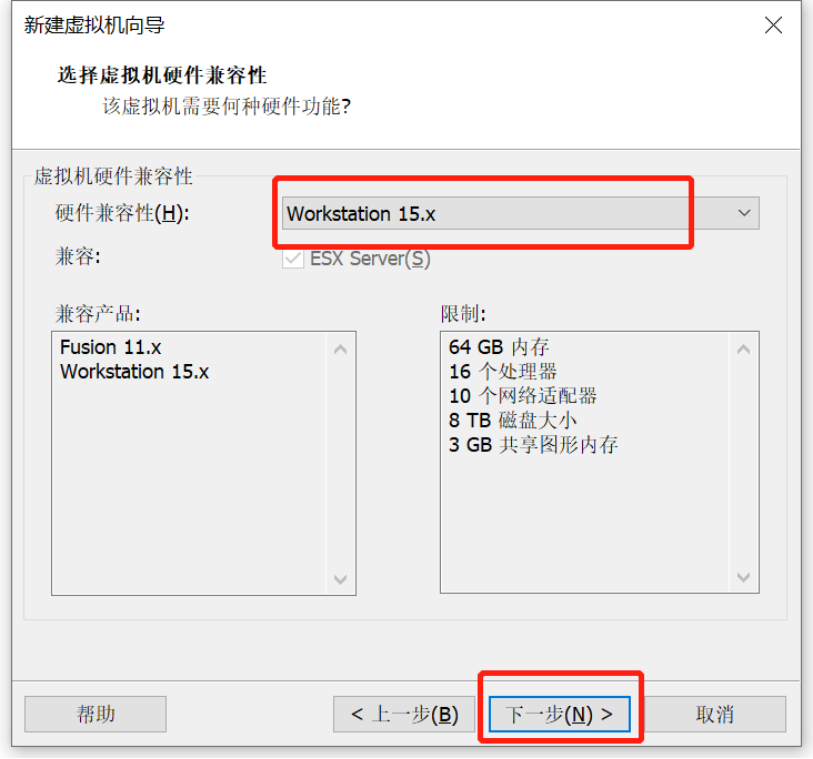
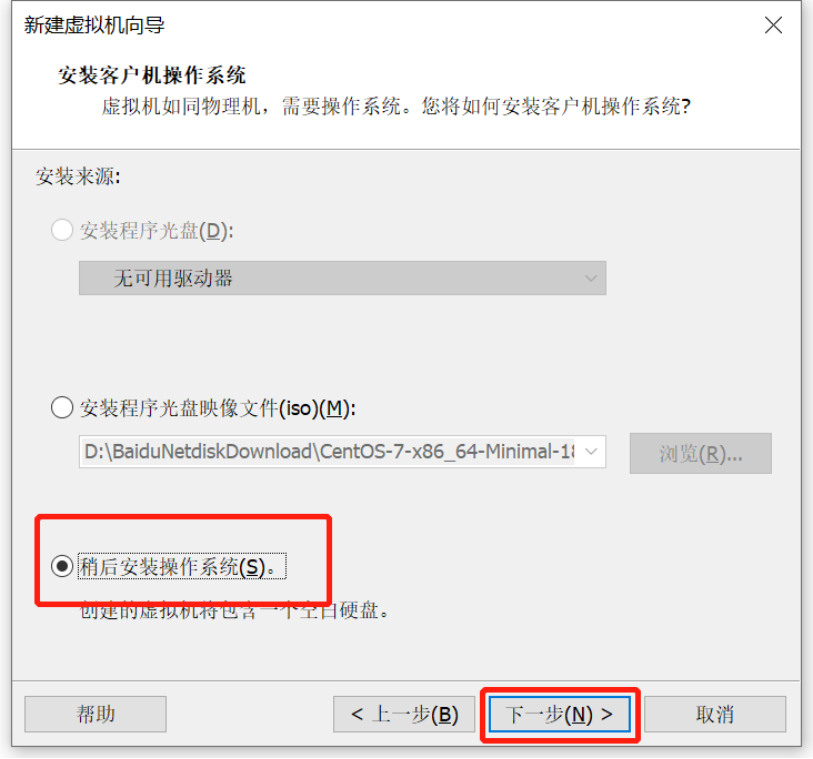
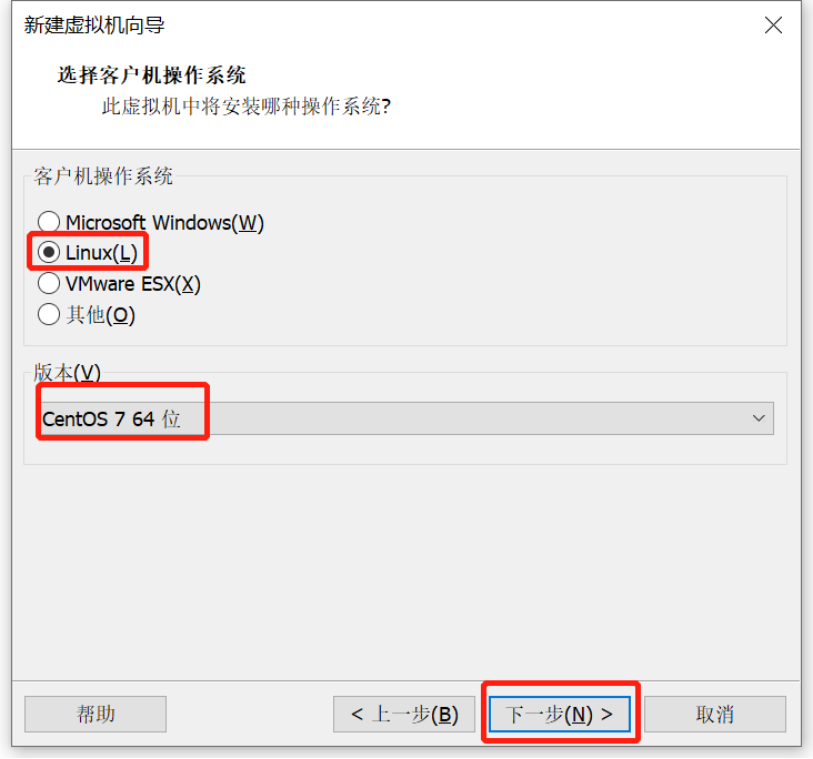
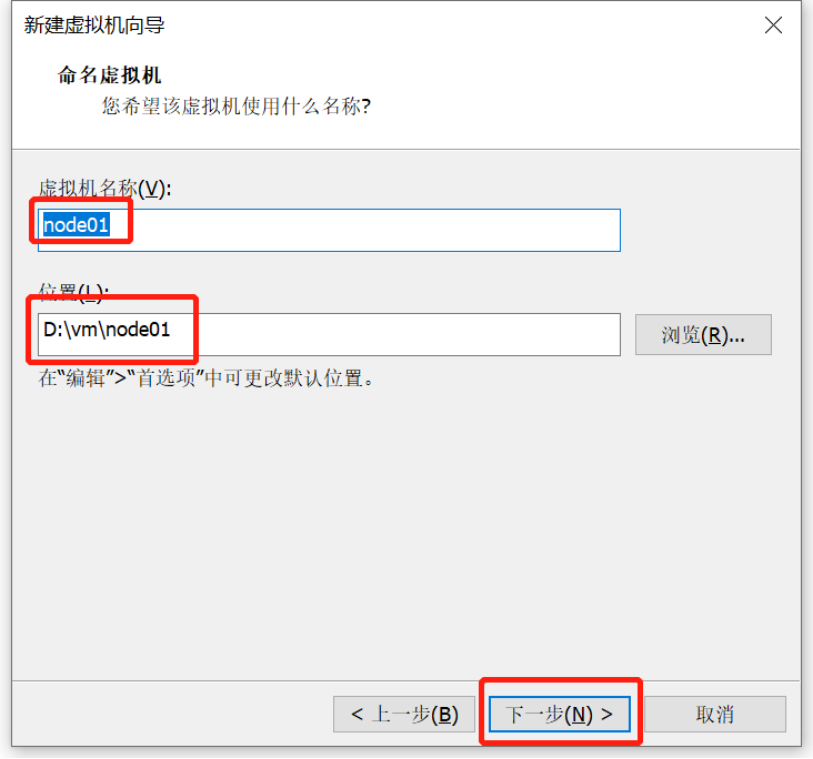
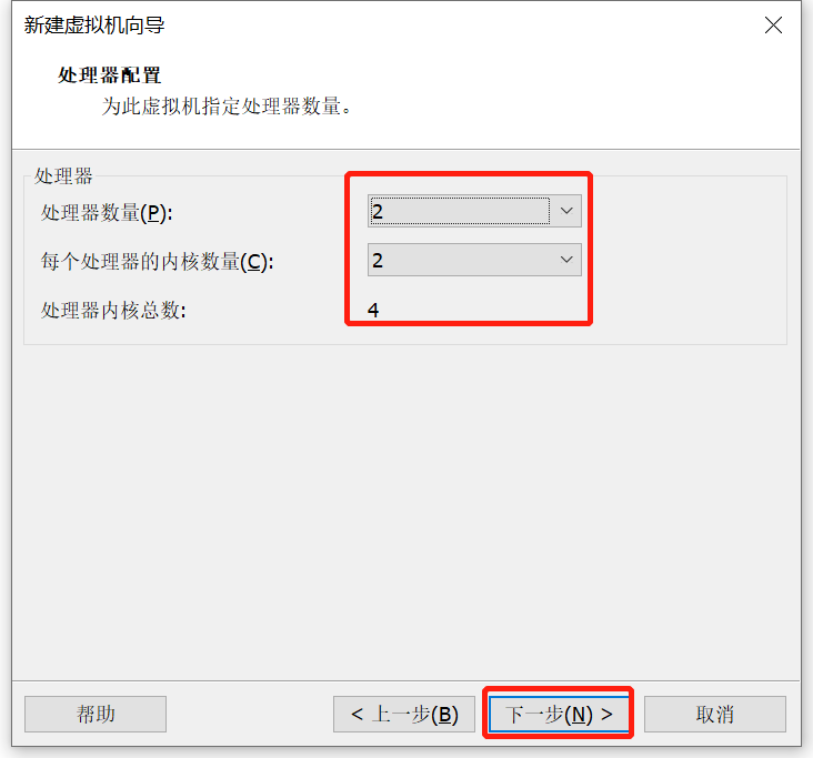
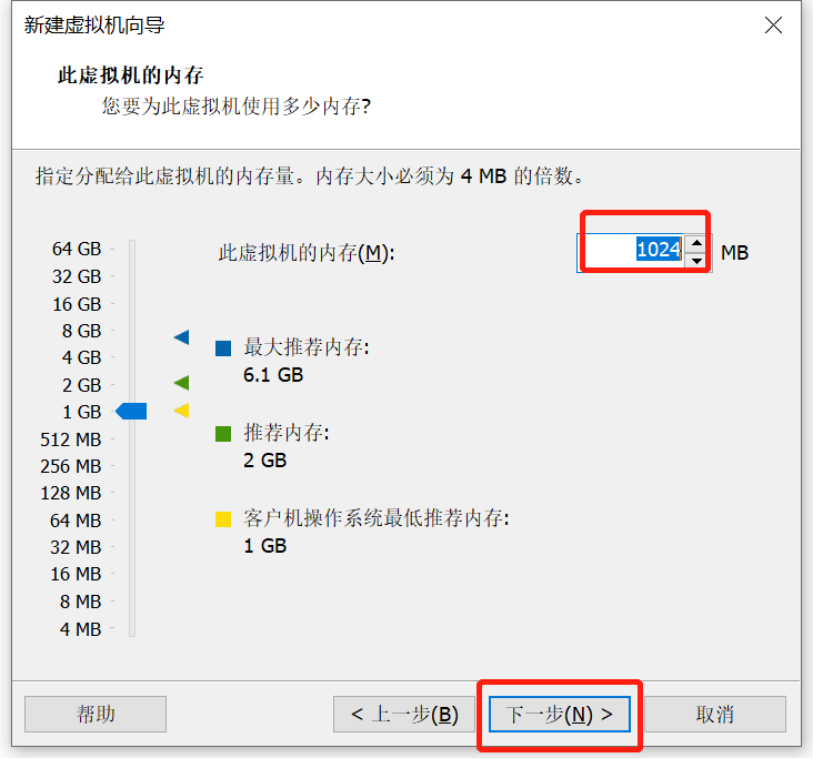
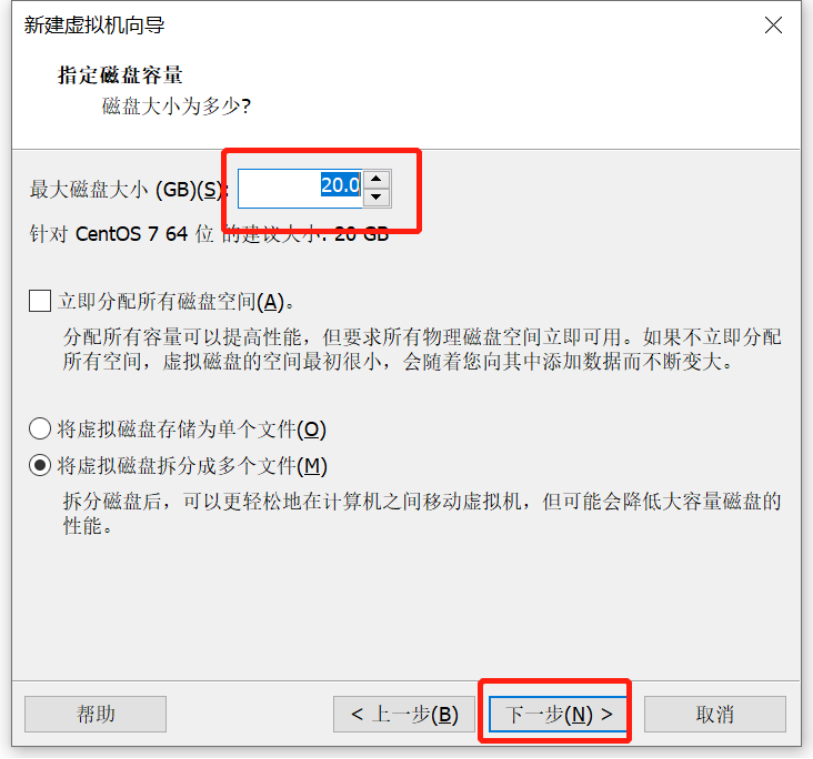
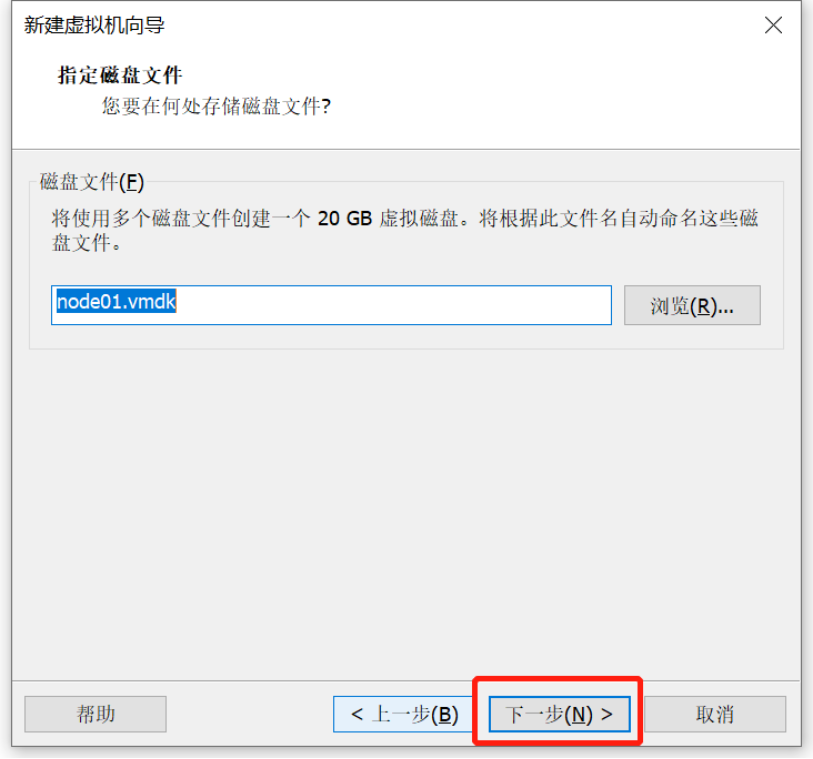
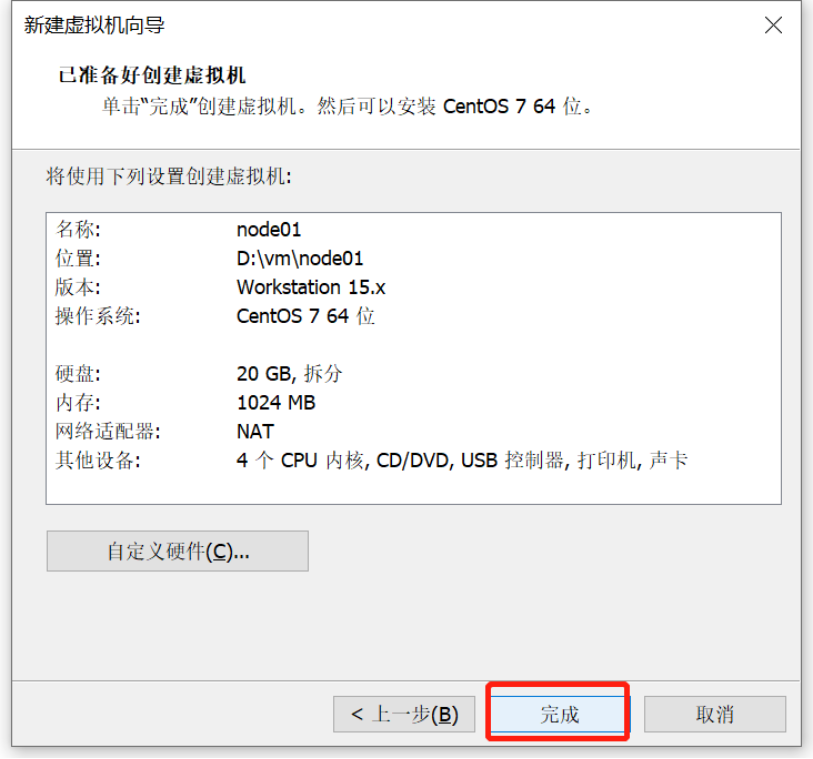 Linux操作系统安装
Linux操作系统安装
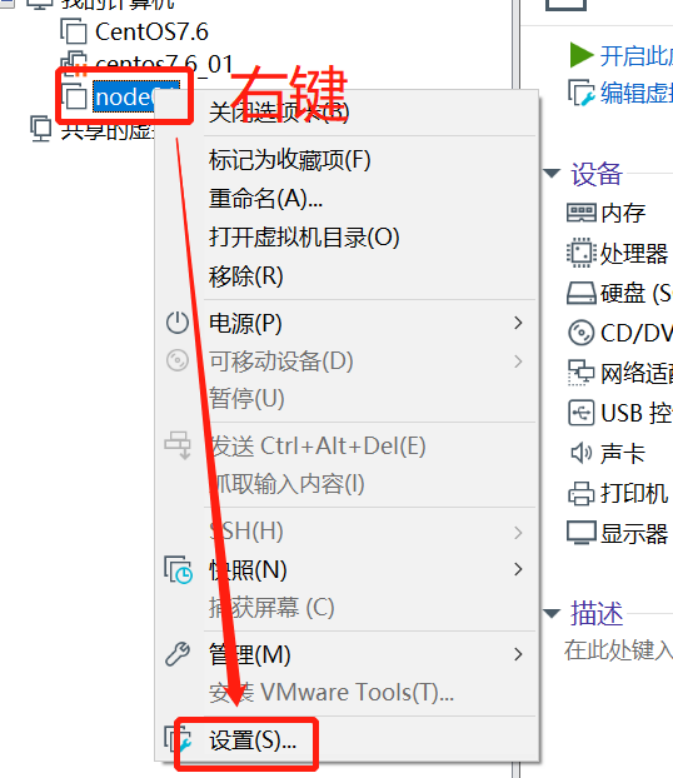
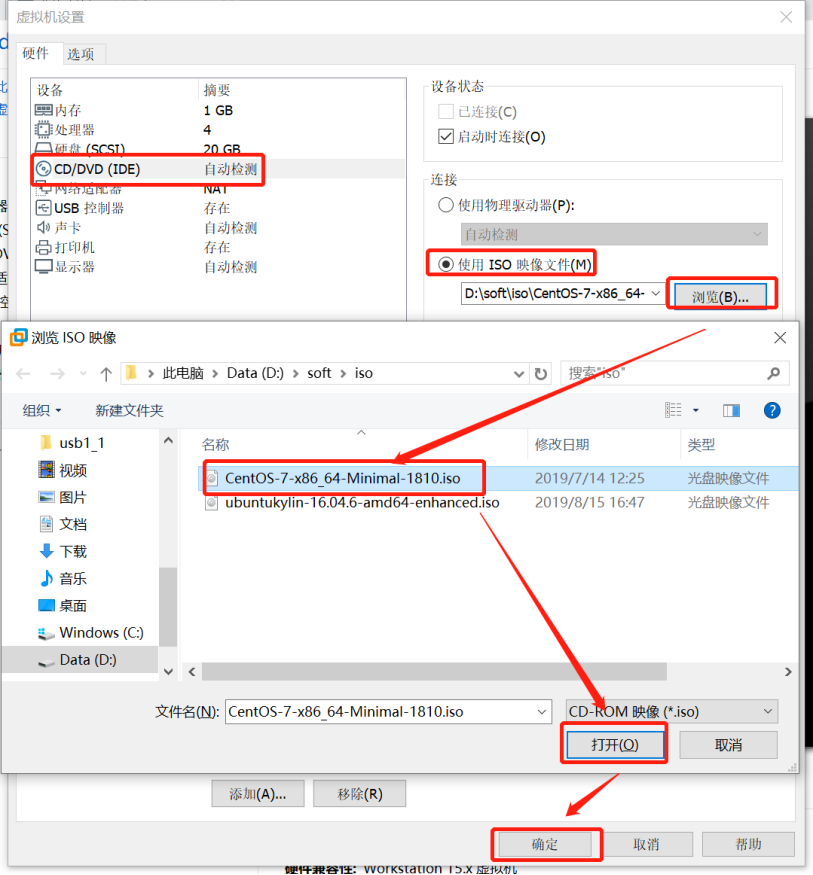
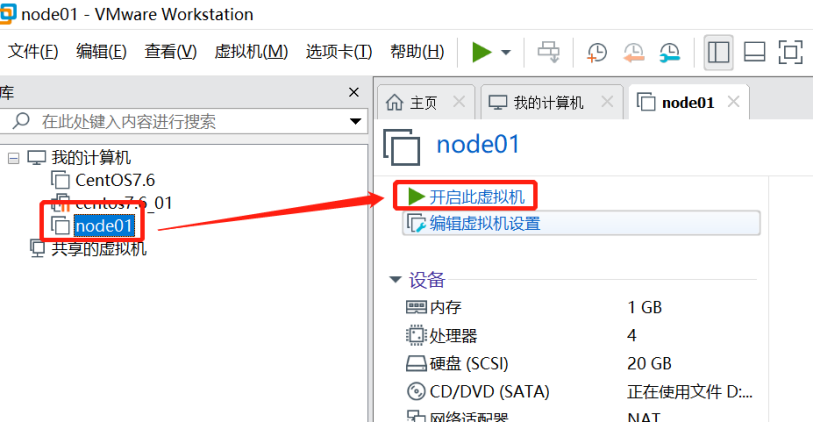
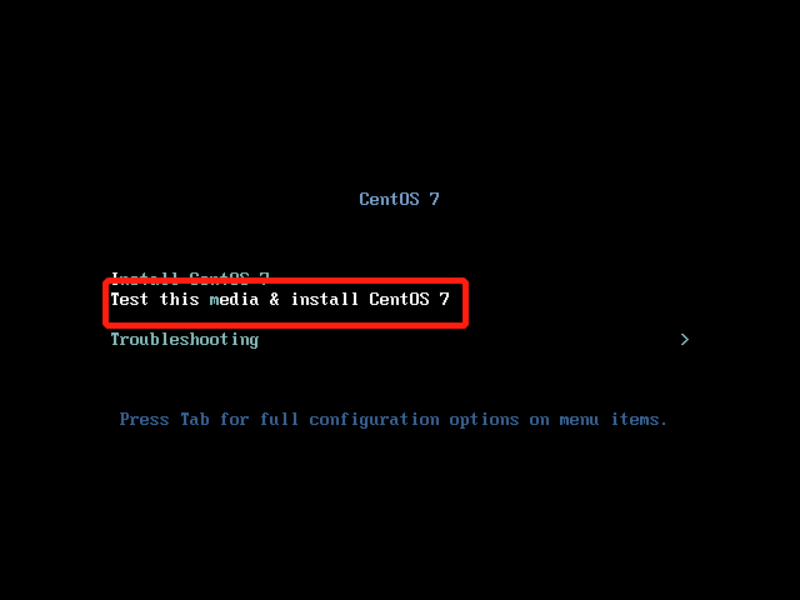
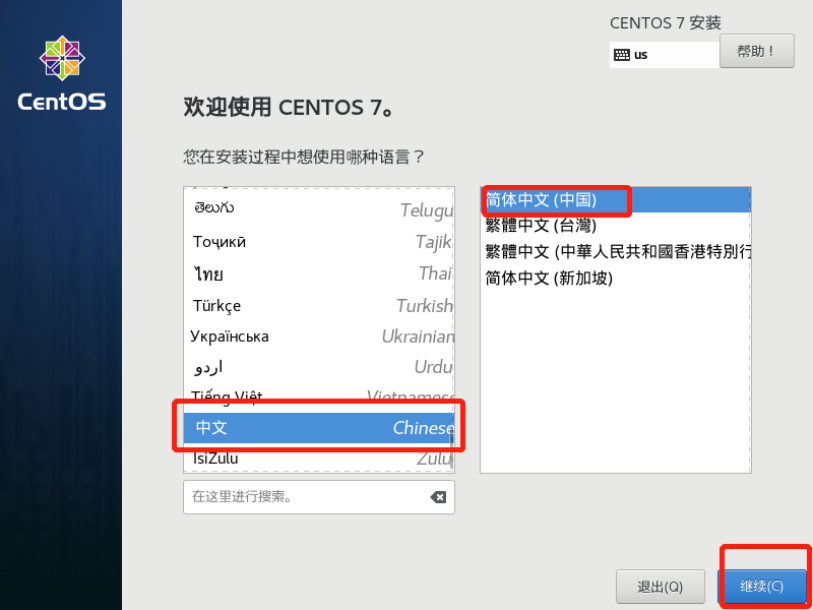
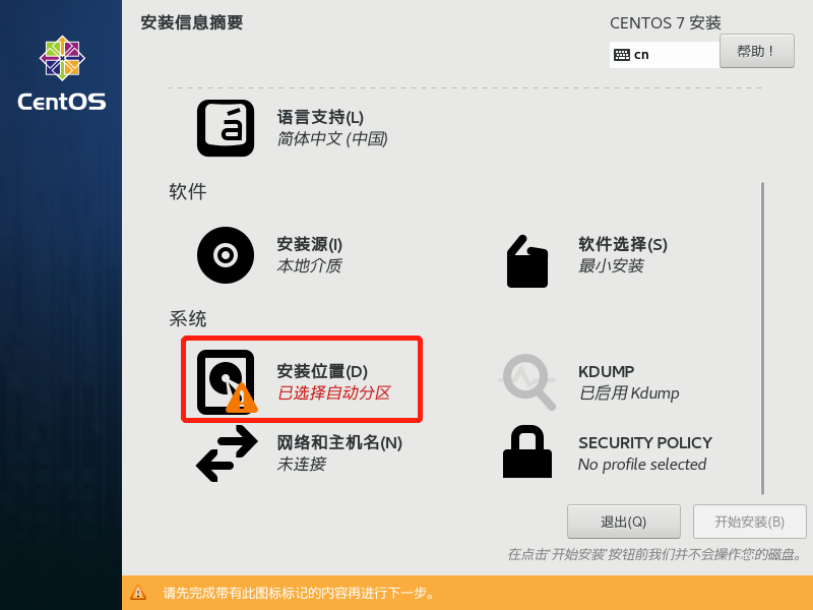
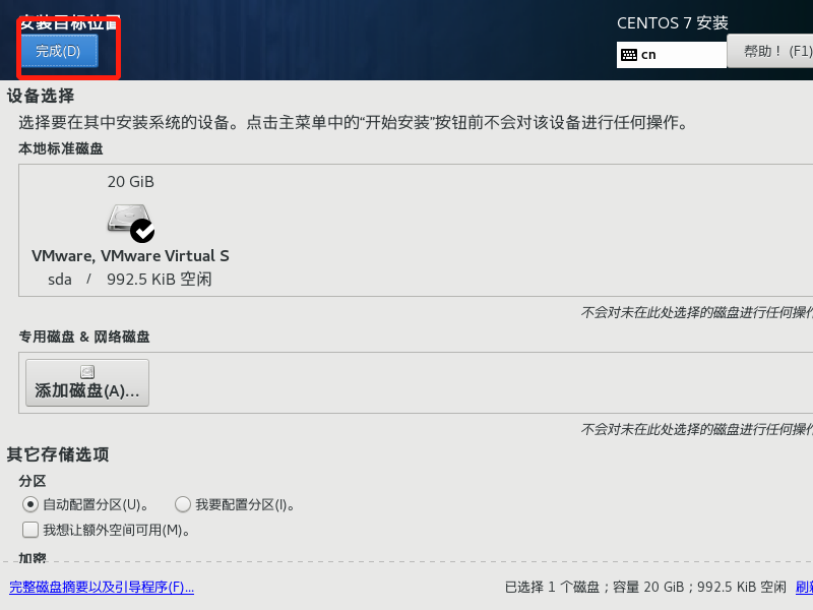

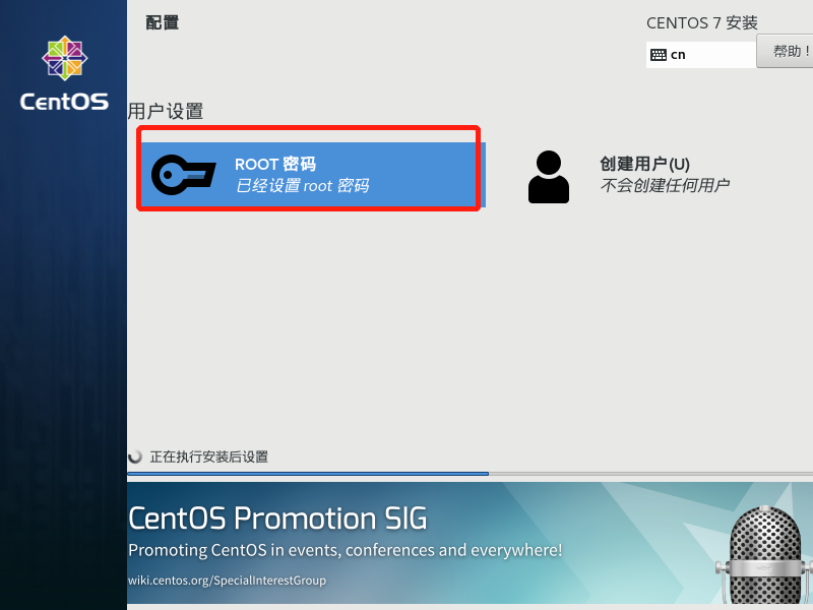
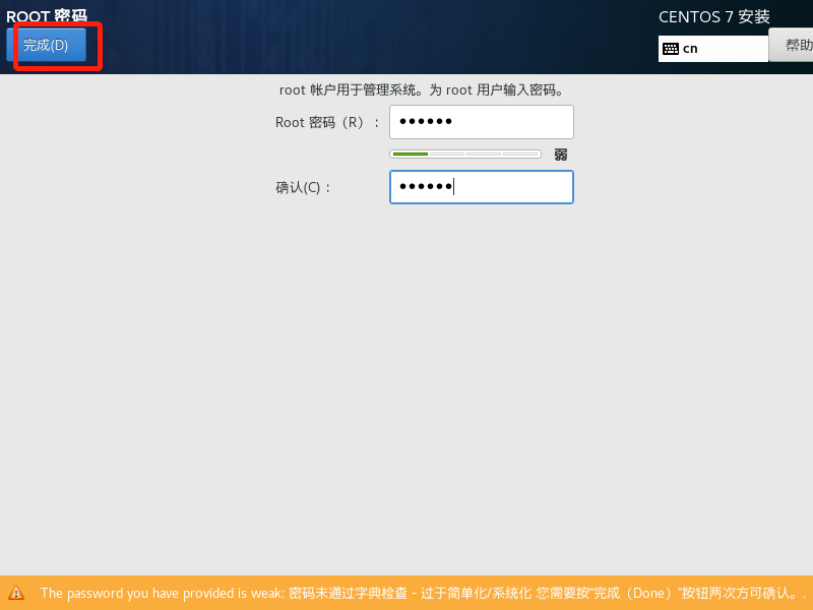



虚拟机拍照
- 关闭虚拟机
- 快照
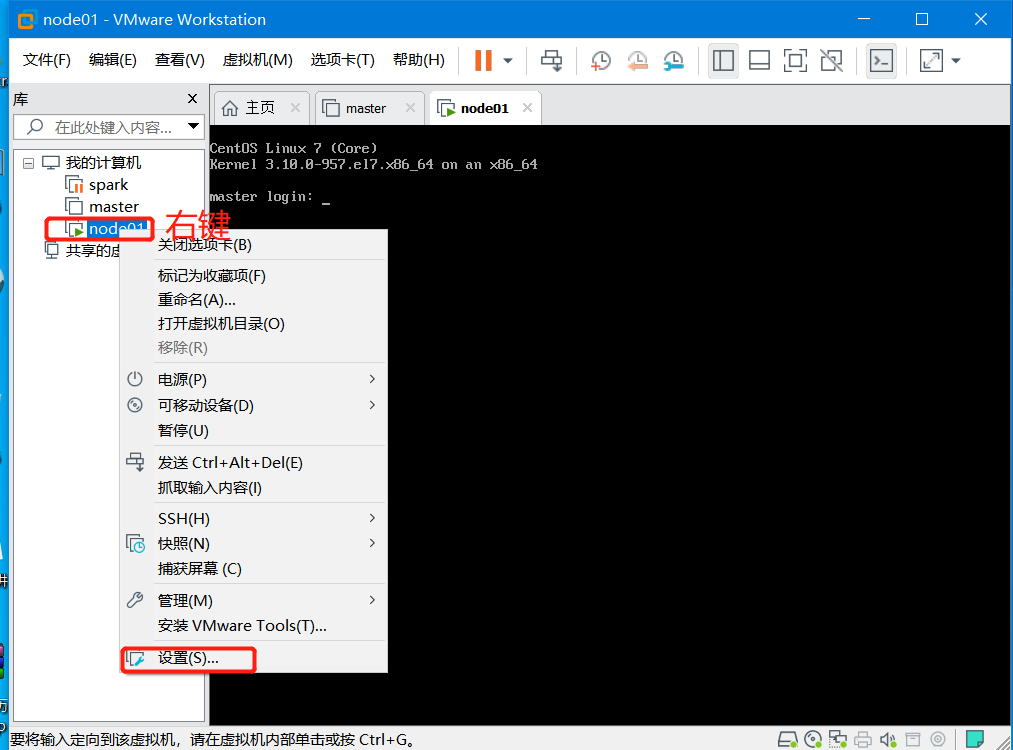
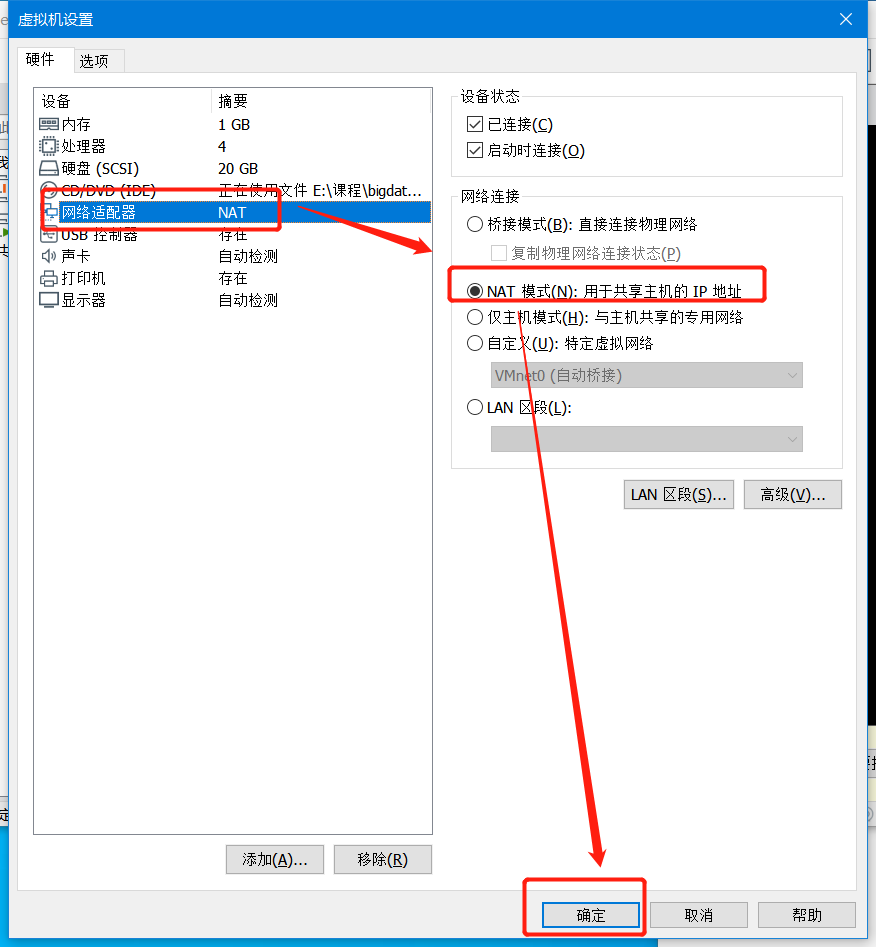
虚拟机网络适配器设置
选择联网模式
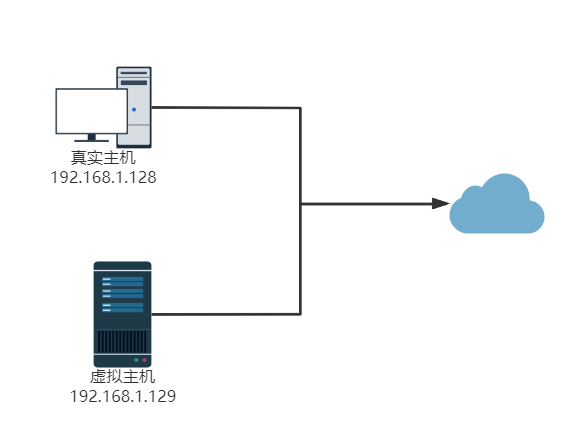
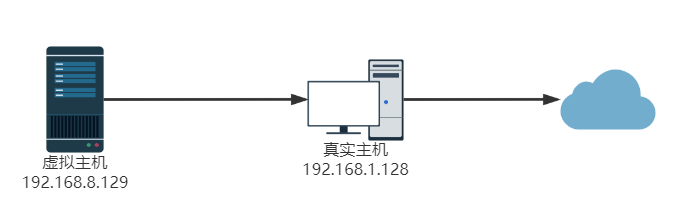
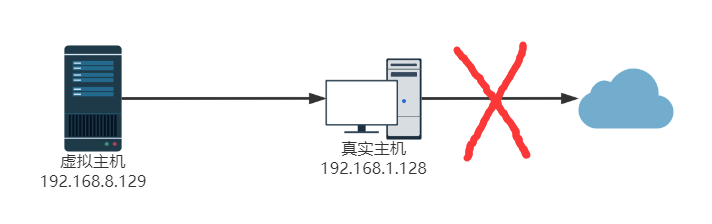
- 桥接模式

- Nat模式
- 仅主机模式
编辑虚拟网络
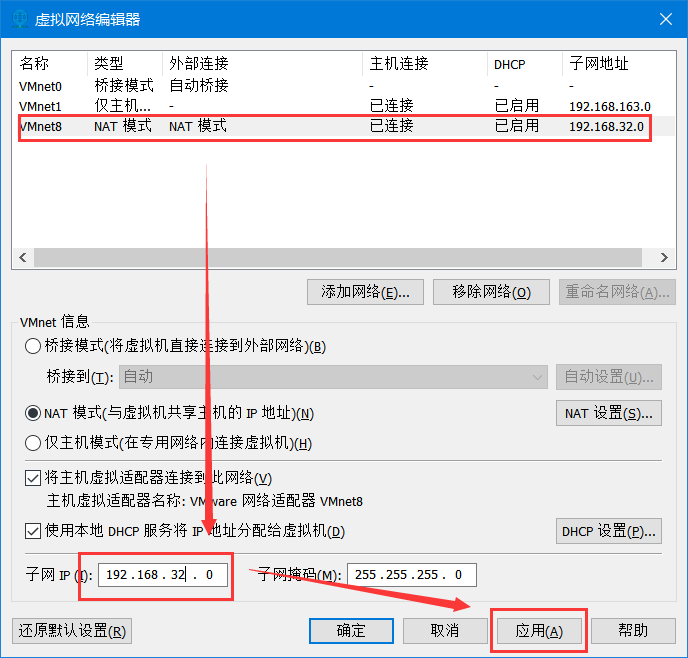 配置IP地址
配置IP地址

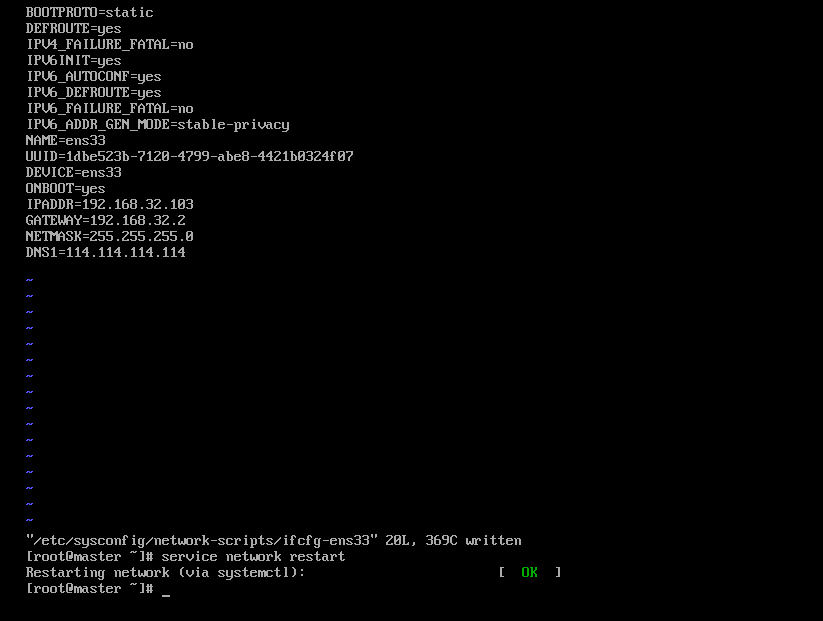
1 | #修改 |
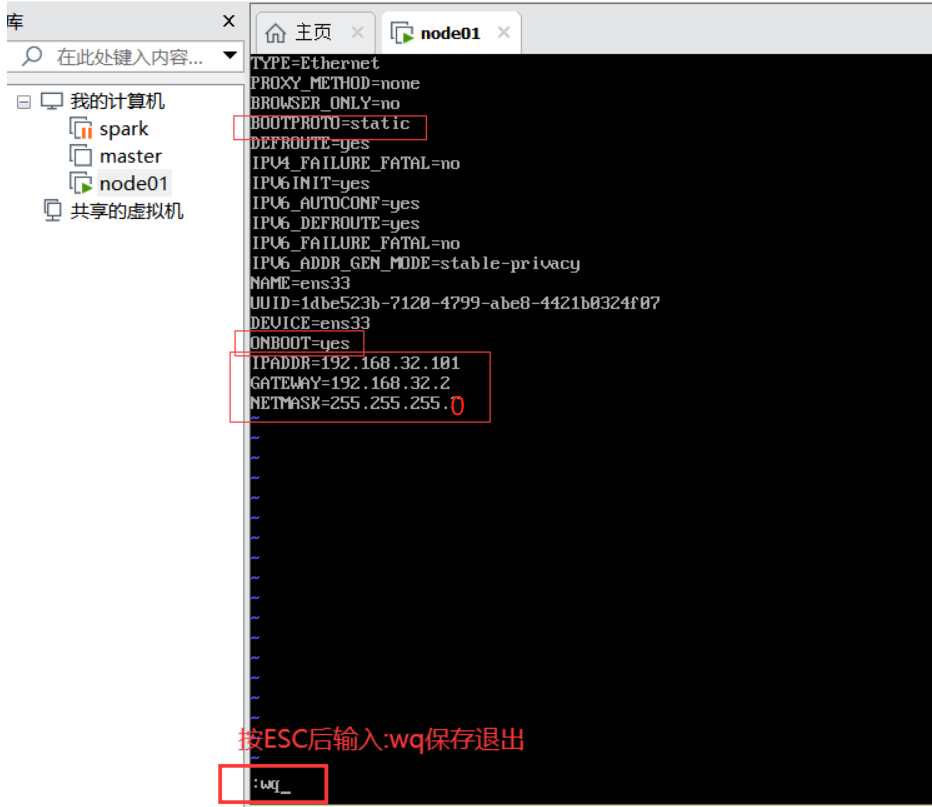
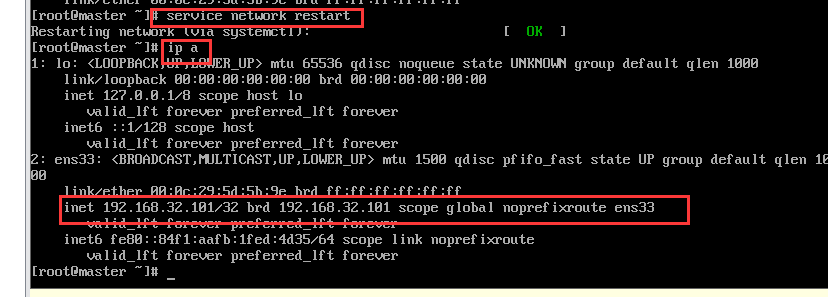
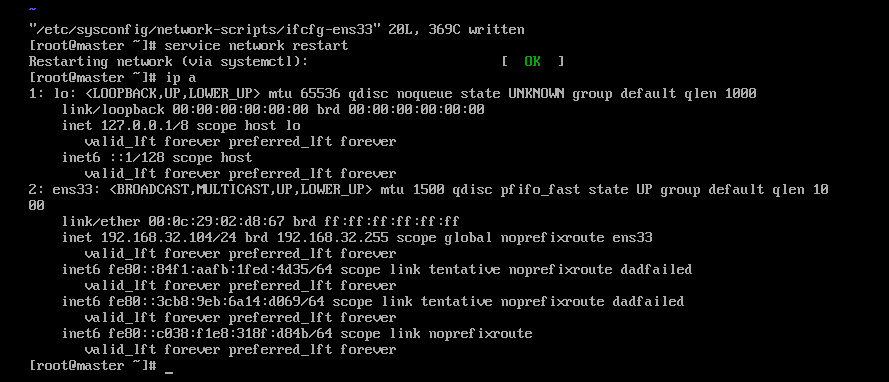
1 | #重启网卡 |
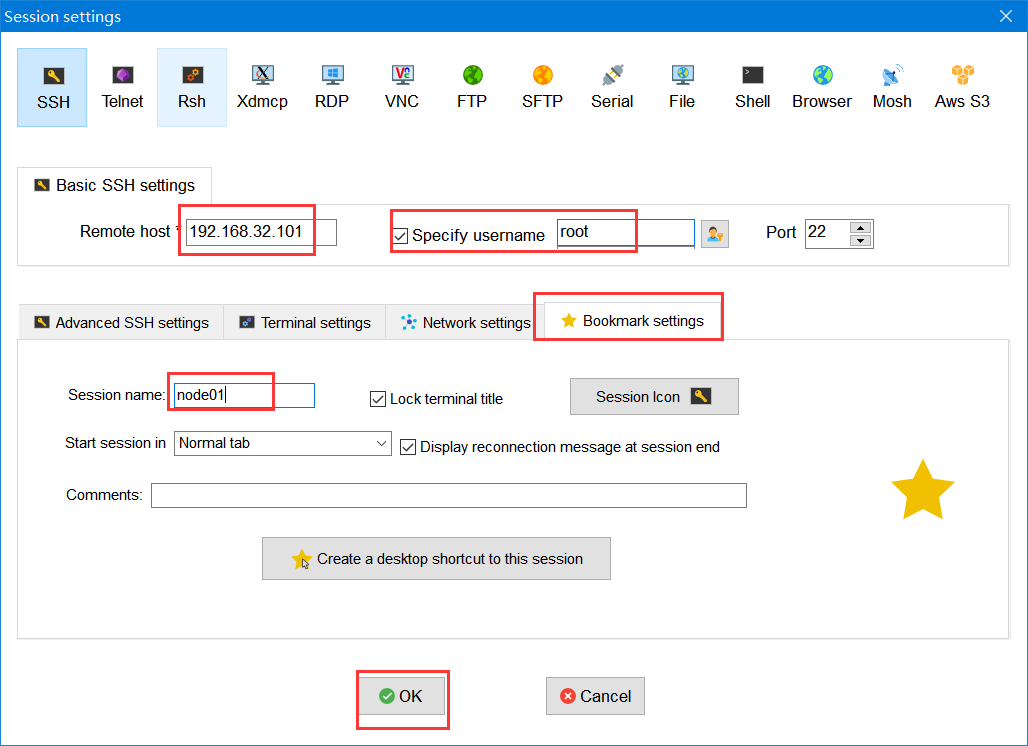
 MobaXterm连接
MobaXterm连接
Linux安全机制
- 关闭防火墙
- 关闭防火墙开机启动
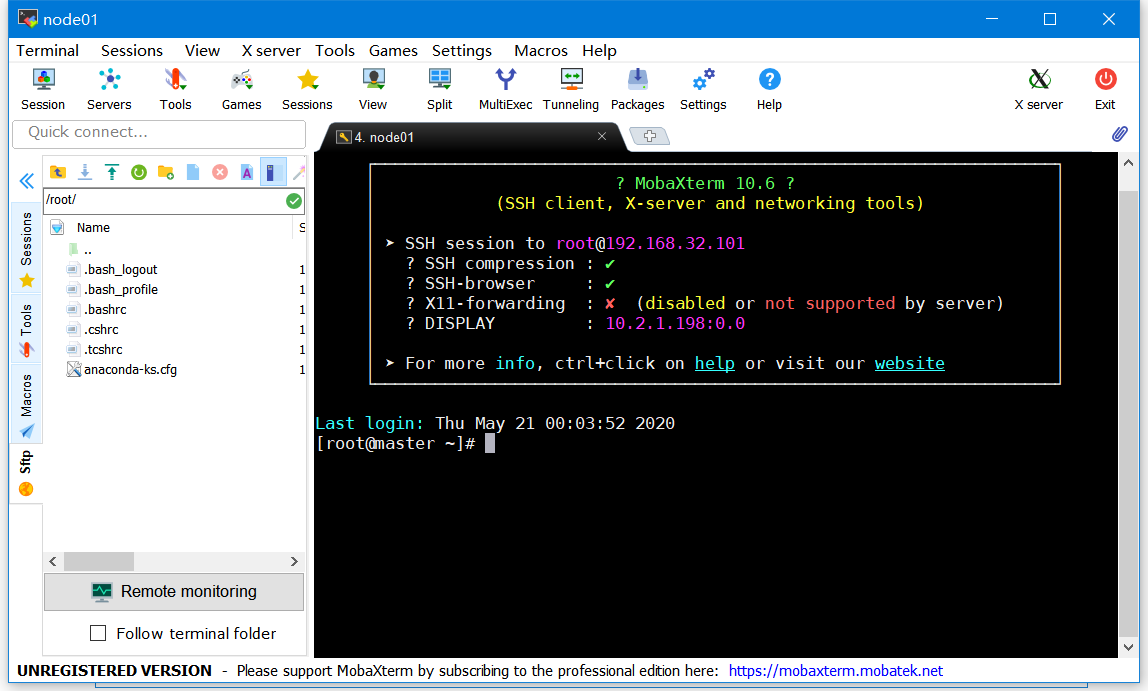
- 修改SELinux配置文件
1
2
3
4[root@master ~]# systemctl status firewalld.service
[root@master ~]# systemctl stop firewalld.service
[root@master ~]# systemctl disable firewalld.service
[root@master ~]# vi /etc/selinux/config
安装JDK
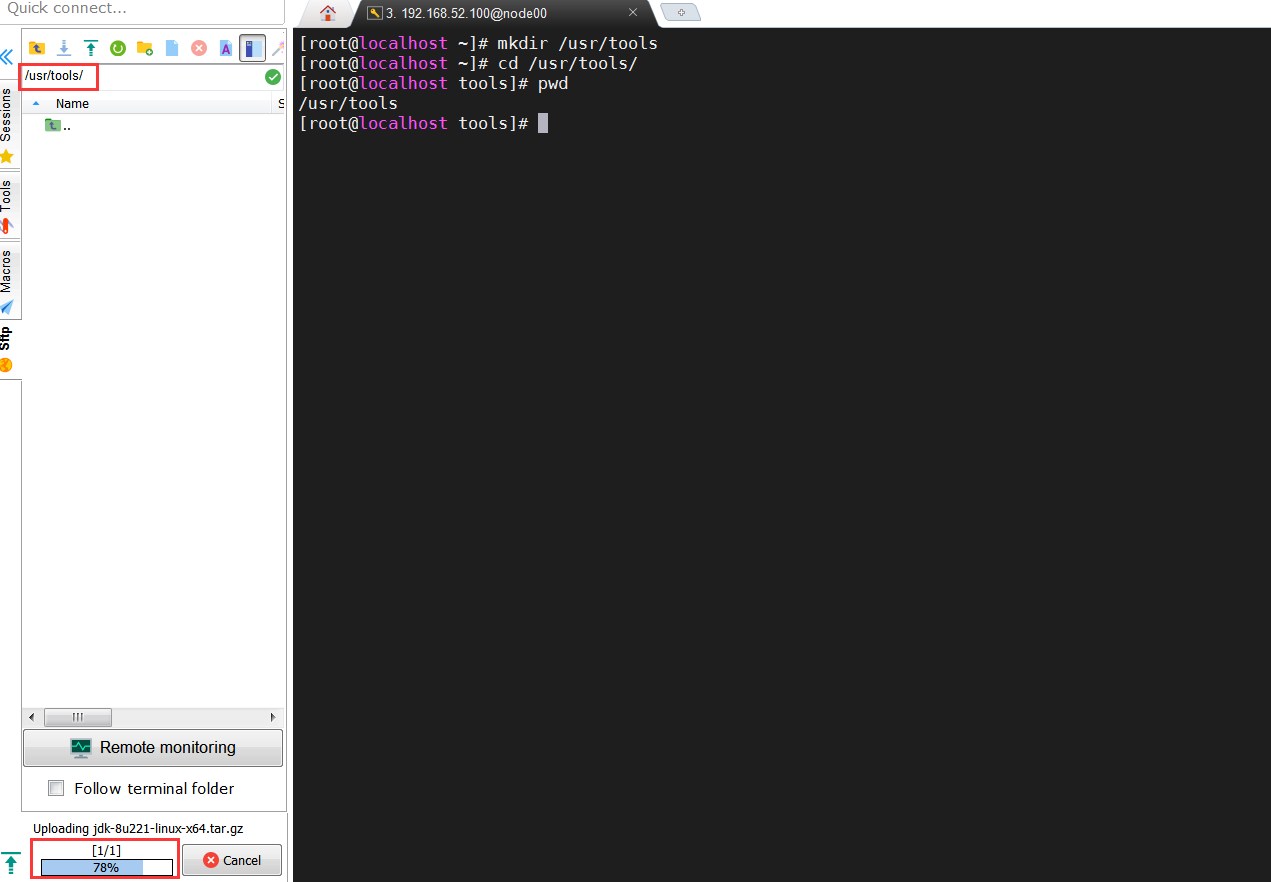
创建一个存放软件的目录
1
2
3[root@localhost ~]# mkdir /usr/tools
[root@localhost ~]# cd /usr/tools/
[root@localhost tools]# pwd上传jdk压缩包到/usr/tools目录下
解压
1
[root@localhost tools]# tar -zxvf jdk-8u221-linux-x64.tar.gz -C /usr/local/
设置环境变量
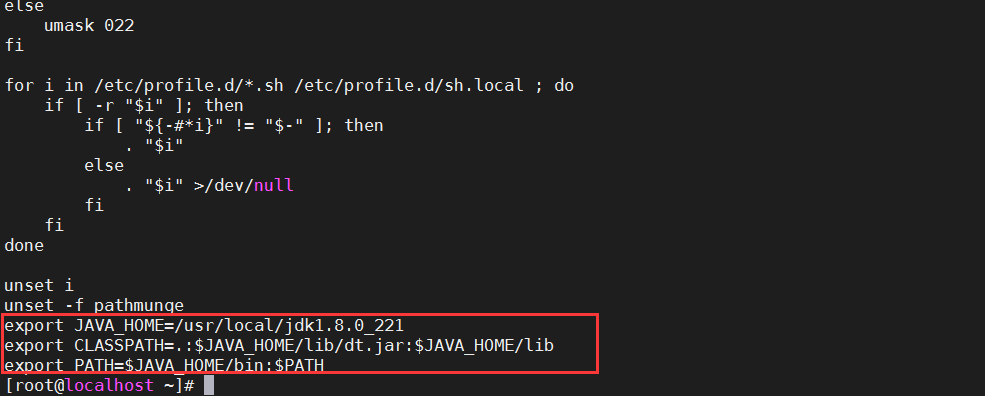
将如下配置添加至文件/etc/profile中,然后保存退出。1
2
3
4
5#java
export JAVA_HOME=/usr/local/jdk1.8.0_221
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH让配置文件生效
1
[root@node01 java]# source /etc/profile
验证
1
[root@node01 java]# java -version



再次拍照
- 关机
- 拍照
集群复制
克隆节点
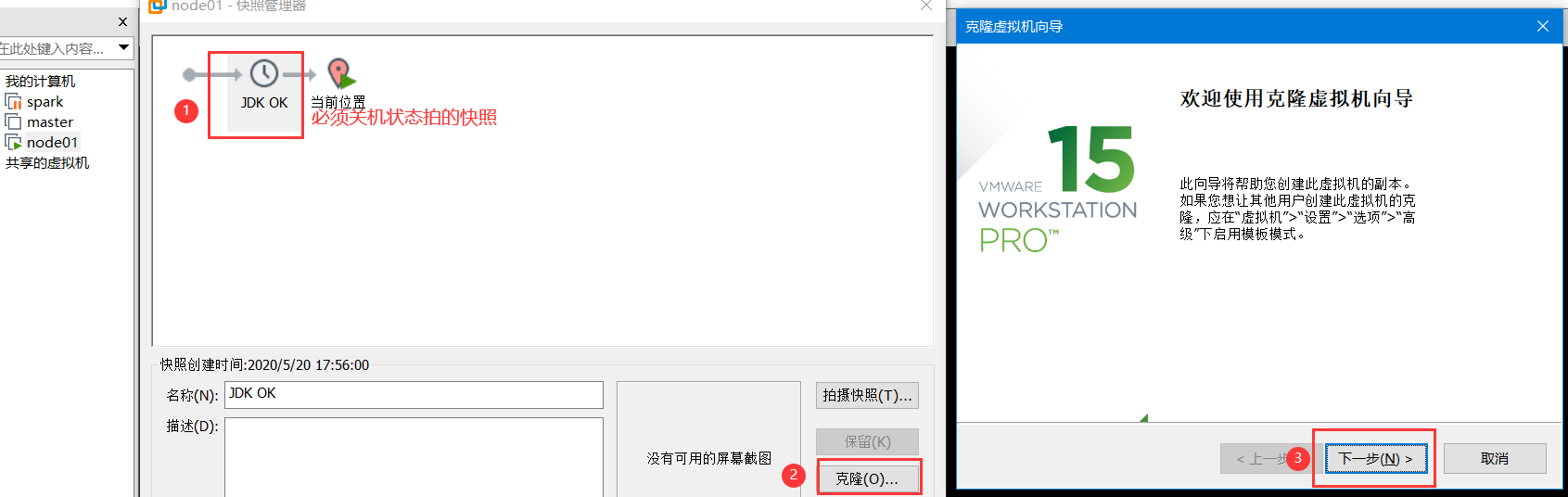
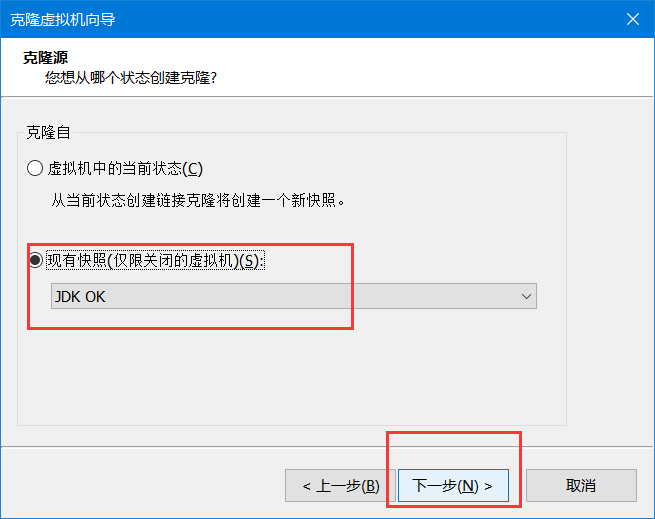
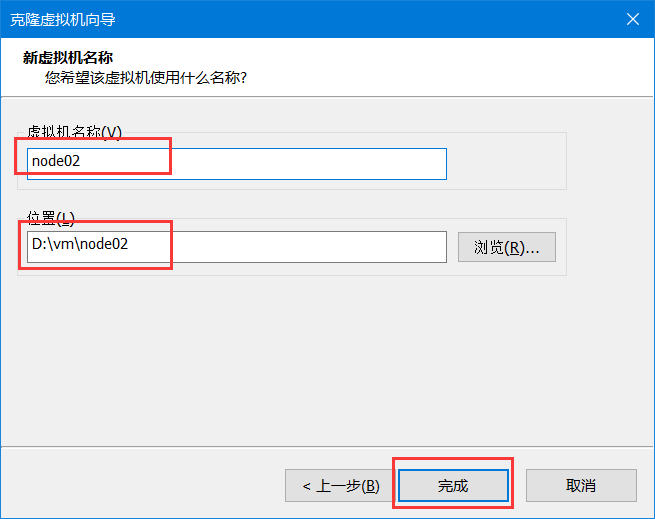
再重复此操作创建出Node02 node03
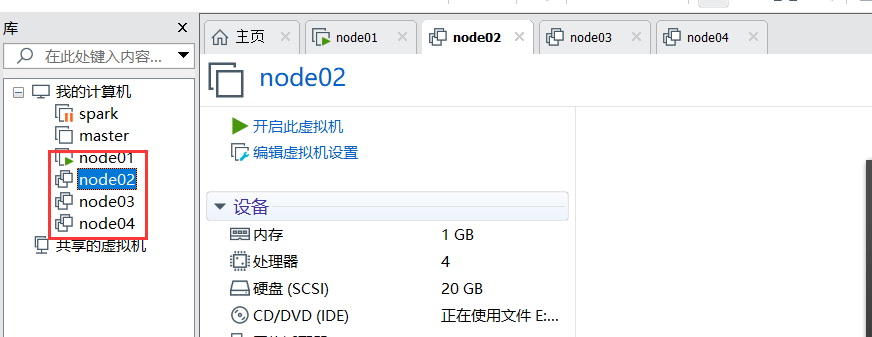
配置IP

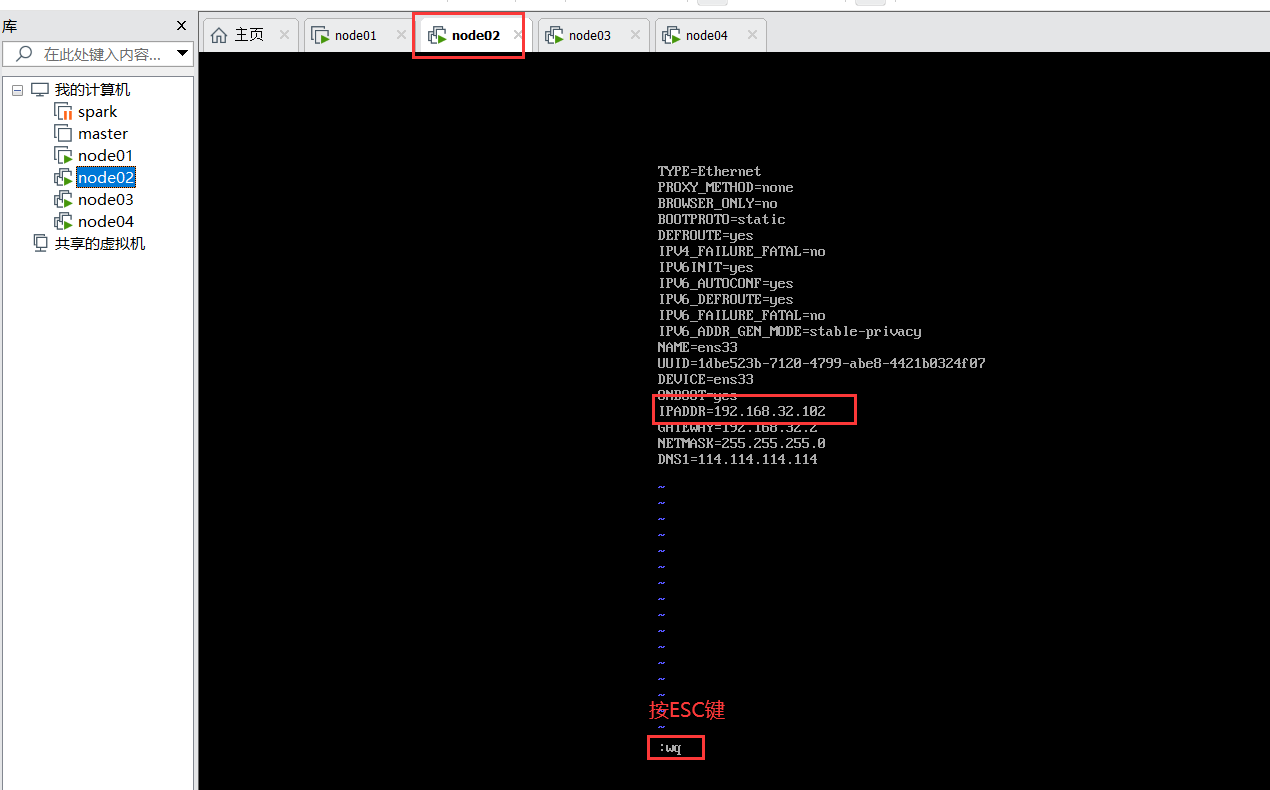
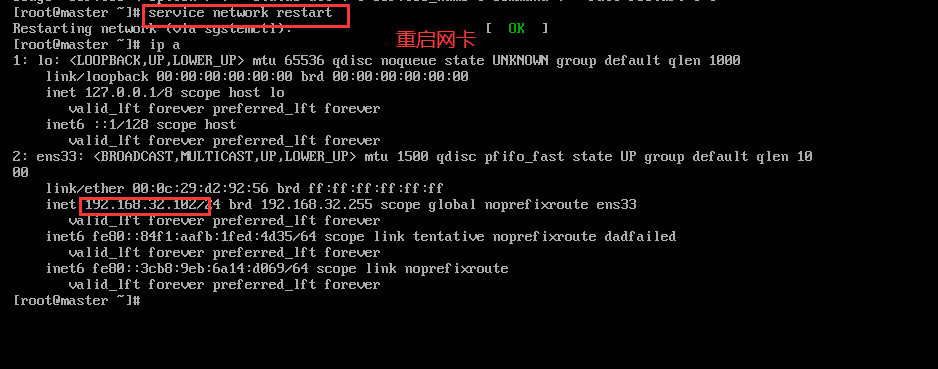
其它2台对应修改
修改主机名
MobaXterm连上4台机器,修改主机名
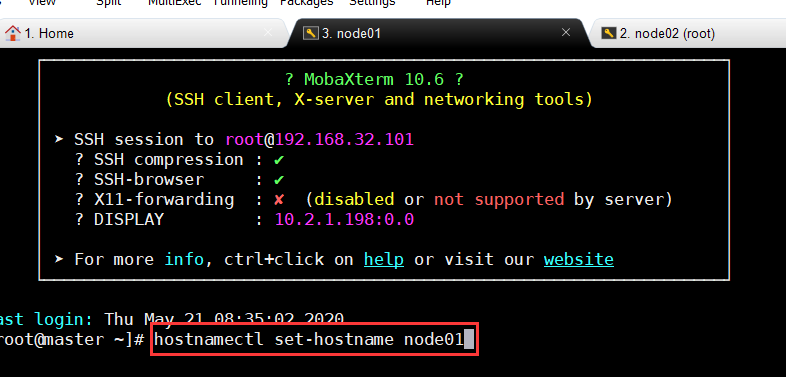
1 | hostnamectl set-hostname node01 |
1 | hostnamectl set-hostname node02 |
1 | hostnamectl set-hostname node03 |
关机创建拍照
Hadoop安装配置
虚拟机IP映射
在node01上编辑 /etc/hosts,加入如下内容
1 | 192.168.52.101 node01 |
SSH免密登录
所有机器依次执行
执行过程中需要输入密码,就输入对应密码即可。
1 | ssh 127.0.0.1 |
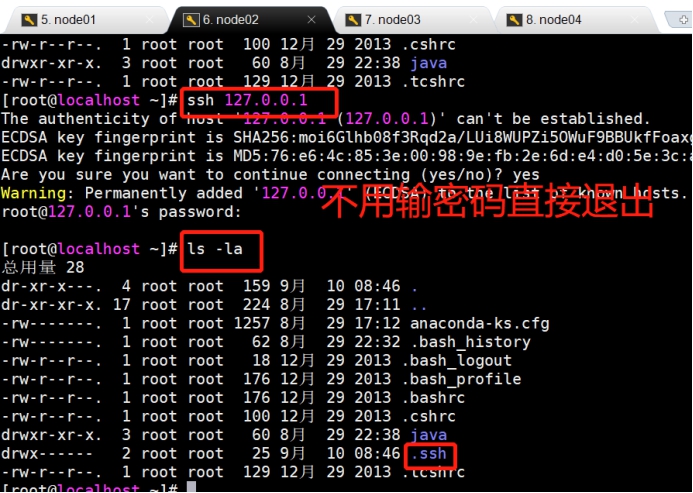
在node01创建秘钥
下面的命令一行一行的运行,运行过程中如果要输入密码,输入即可。
1 | ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa |
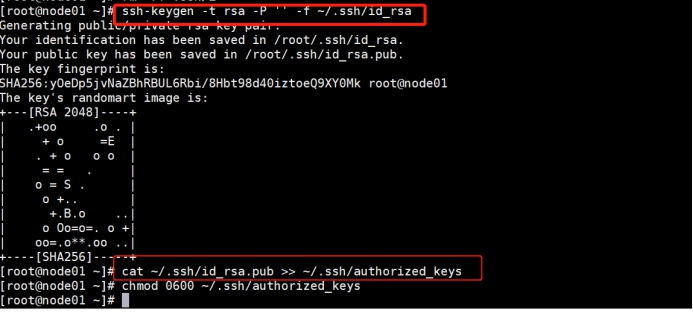
共享公钥
在node01将公钥推给另外节点,执行:
可能要输入密码,输入即可
1 | [root@node01 ~]# ssh-copy-id -i node01 |
验证
连的过程中有可能第一次需要输入密码,第二次再去ssh还是需要输入密码就有问题,
注意事项:一旦ssh连进去了之后一定要退出来,exit
1 | ssh node02 |
1 | ssh node03 |
1 | ssh node04 |
分发hosts文件
把hosts文件分发给node02 node03
1 | [root@node01 ~]# scp /etc/hosts root@node02:/etc/ |
node01(主)安装Hadoop
上传
解压
1
2
3
4
5[root@node01 ~]# cd /usr/tools/
[root@node01 local]# tar -zxvf hadoop-2.7.7.tar.gz -C /usr/local
[root@node01 hadoop-2.7.7]# cd /usr/local/hadoop-2.7.7/share/
[root@node01 share]# ls doc
hadoop[root@node01 share]# rm -rf doc设置环境变量
1
vi /etc/profile
添加如下内容
1
2# Hadoop
export HADOOP_HOME=/usr/local/hadoop-2.7.7export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH环境变量生效
1
[root@node01 ~]# source /etc/profile
测试验证
1
hadoop
分发环境变量
1 | scp /etc/profile root@node02:/etc/ |
配置Hadoop全分布式
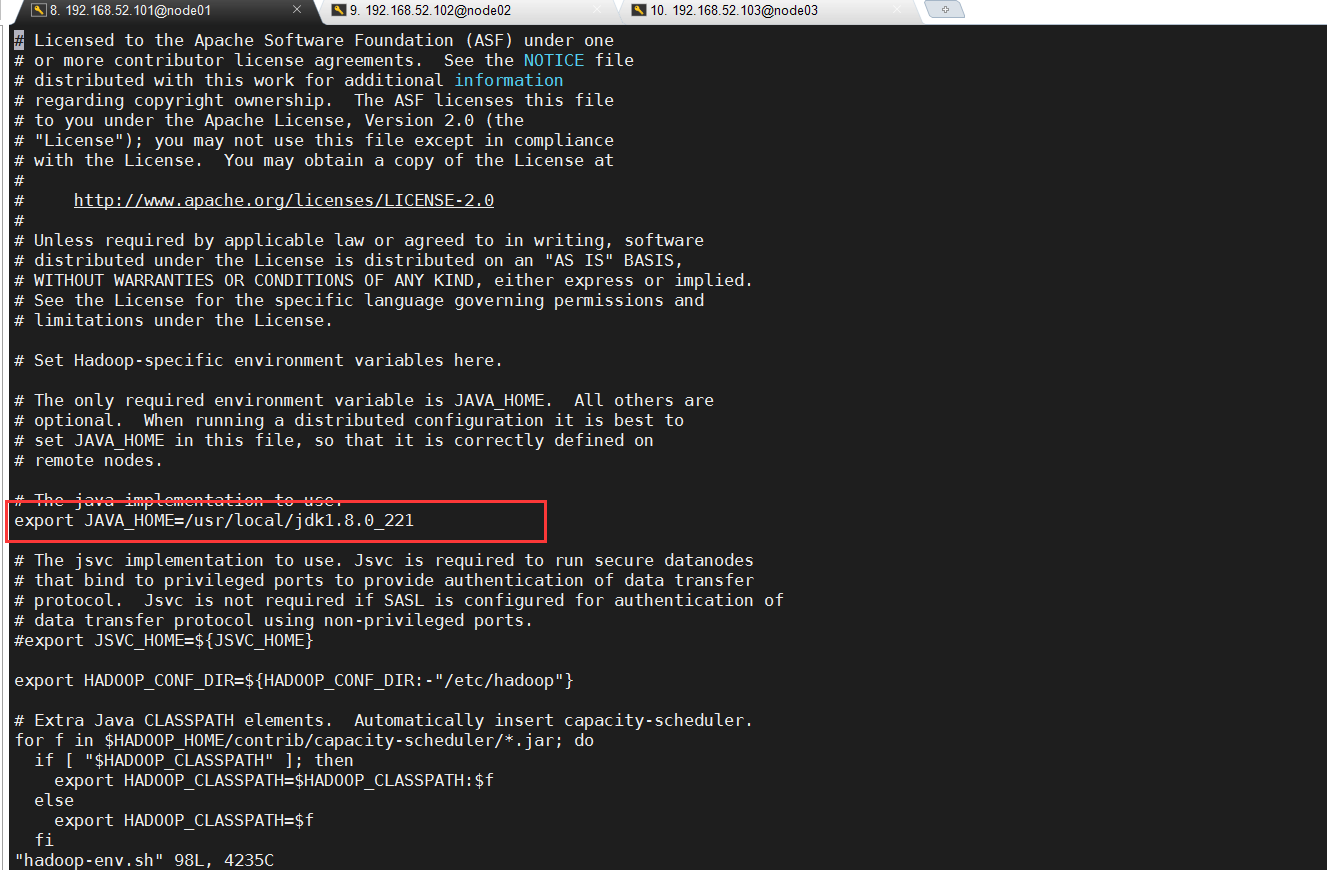
修改hadoop-env.sh

1 | export JAVA_HOME=/usr/local/jdk1.8.0_221 |
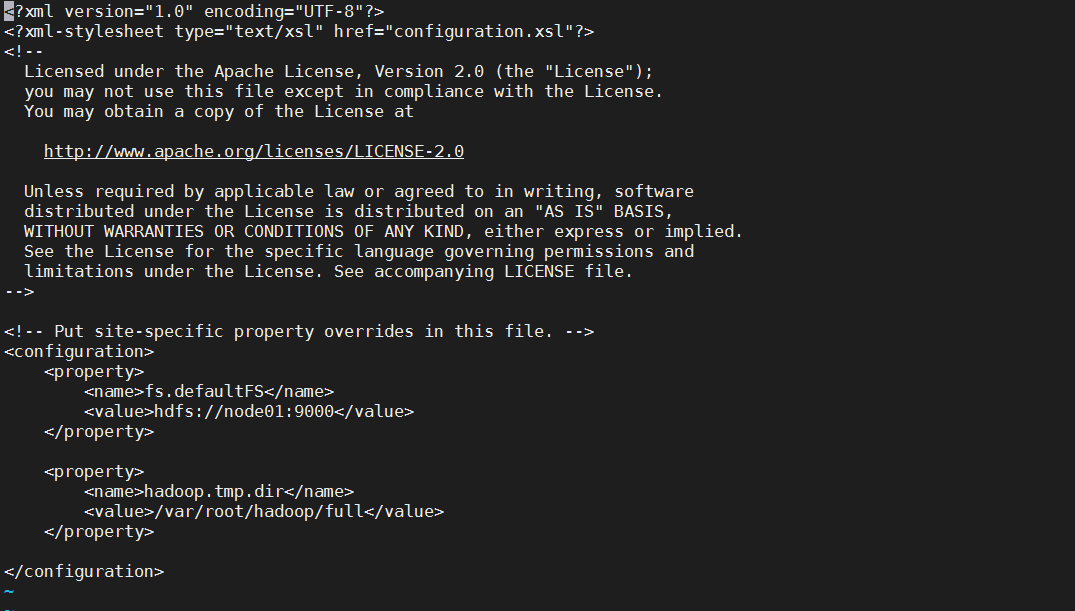
修改core-site.xml

1 | <configuration> |
说明:
- fs.defaultFS 文件系统对外提供的URI地址以供数据交互。
- hadoop.tmp.dir是hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site.xml中不配置namenode 和datanode的存放位置,默认就放在这个路径下。
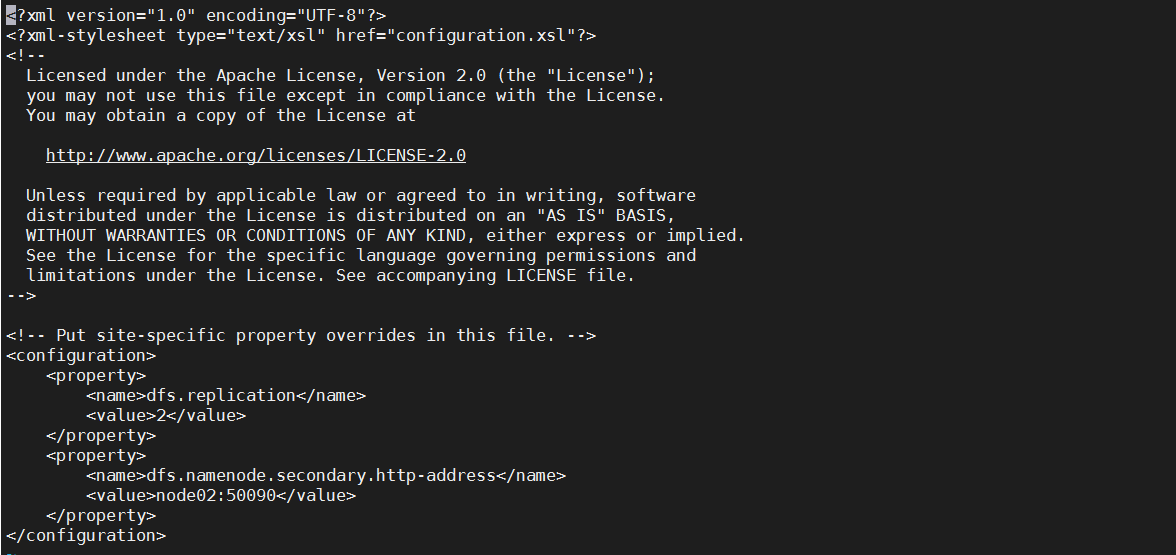
修改hdfs-site.xml

1 | <configuration> |
说明:
- dfs.replication 副本数量
- dfs.namenode.secondary.http-address 提供secondary namenode的节点和端口
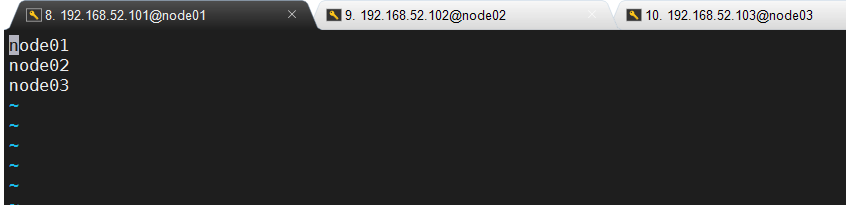
修改slaves

1 | node01node02node03 |
修改yarn-site.xml

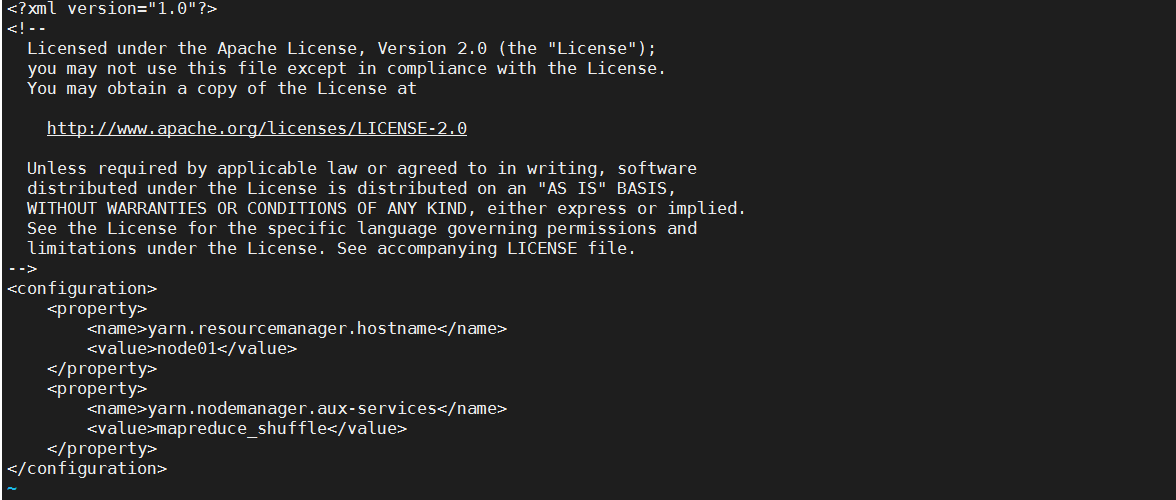
1 | <configuration> |
分发hadoop到各节点
1 | scp -r /usr/local/hadoop-2.7.7 root@node02:/usr/local |
格式化和启动
- 在Node01节点格式化操作
1
hdfs namenode -format
- 启动(只需要在主节点上启动,其他的不需要启动)
1
start-dfs.sh
- 验证
1
jps
- **登陆web地址([**http://192.168.52.101:50070/)检测
总结
Hadoop的全分布式搭建的过程:
- 准备3台虚拟机
- 保证虚拟机网络、IP、主机名、防火墙
- 安装JDK
- 做etc hosts文件设置
- 免秘钥登陆
- 安装Hadoop
- 上传包 解压
- 配置环境变量
- 让环境变量生效 验证
- hadoop-env.xml 配置JAVA_HOME
- core-site.xml namenode
- hdfs-site.xml
- slaves 从节点
- yarn-site.xml
- 分发Hadoop
- 格式化 hadoop namenode -format
- 启动 start-dfs.sh stop-dfs.sh
- 检查 JPS


评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果