Hive基本应用操作
Hive基本应用操作
urcuteimmehingeHive的应用操作
Hive的HQL语句底层执行的机制原理
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能.说白了,hive就是MapReduce客户端,将用户编写的HQL语法转换成MapReducer程序进行执行。
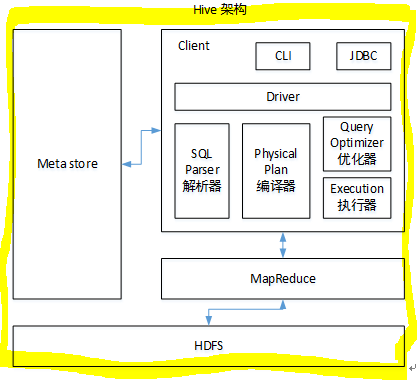
如图中所示,总的来说,Hive是通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
- 用户接口:Client
CLI(hiveshell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive) - 元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中
使用HDFS进行存储,使用MapReduce进行计算。 - 驱动器:Driver
- 解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
- 编译器(Physical Plan):将AST编译生成逻辑执行计划。
- 优化器(Query Optimizer):对逻辑执行计划进行优化。
- 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MapReduce/Spark。 这是Hive官网对于HQL语句的文档说明
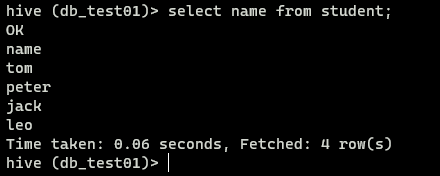
查询数据
1 | #格式: select 字段名 from 表名; |
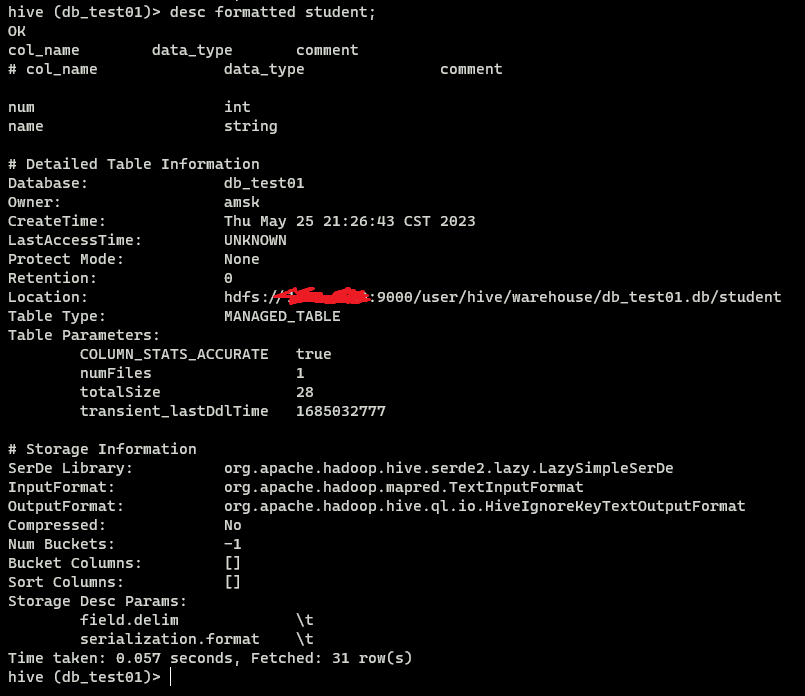
查看表结构
- 方式一
1 | #格式: desc数据表名称; |

- 方式二
1 | #格式: desc extended数据表名称; |
- 方式三
1 | #格式: desc formatted 数据表名称; |

通过Hive查看HDFS文件系统上的目录结构
1 | #由于Hive与HDFs之间建立了连接,我们之前也配置过hive-env.sh文件,指定过Hadoop的配置文件路径,所以Hive和Hadoop之间时刻保持着联通, |
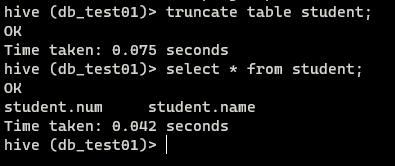
清空表数据
1 | #格式: truncate table 数据表名称; |
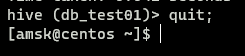
退出Hive
如果不使用Hive了,建议一定要正常退出Hive的交互界面
1 | quit; |
HQL
Hive中的数据库的概念本质上仅仅是表的一个目录或者命名空间,用于管理数据库下的所有表。
操作
- 创建数据库
1
create database [if not exists] 数据库名;
- 删除数据库
1
2
3drop database [if exists] 数据库名 [cascade];
#[if exists]: 判断是否存在
#[cascade]: 表示忽略报错,联级删除
映射
- hive建立一张表跟已经存在的结构化数据文件产生映射关系。映射成功之后,就可以通过写sql来分析这结构化的数据,避免了写MR程序的麻烦。
- 数据库是放在HDFS中/user/hive/warehouse下的一个文件夹对应表。
- 表的数据位置不能随便存放,一定要在指定的数据库文件下面,并且创建表时需要指定分隔符,否则有可能映射不成功。
分隔符
一般
数据:1
2zhangsan,beijiin,shanghao,chengdu
lishi,shanghai,chengdu,wuhan1
2
3
4
5
6
7
8
9
10-- HQL
create table test1(
name string,
city1 string,
city2 string,
city3 string,
city4 string
)row format delimited fields terminated by ',';
# row format delimited : 内置分隔符
# ',' : 字段之间采用‘,’分隔复杂
数据:1
2zhangsan biejing,shanghai,chengdu
lishi shanghai,chengdu,wuhan1
2
3
4
5
6
7-- HQL
create table test1_array(
name string,
work_city array<string>
)
row format delimited fields terminated by ','
collection items terminated by ',';数据:
1
21,zhangsan,唱歌:喜欢-看电影:非常喜欢-运动:不喜欢
2,lishi,打游戏:喜欢-看书:喜欢-运动:非常喜欢1
2
3
4
5
6
7
8
9
10-- HQL
create table test2_map(
id int,
name string,
hobby map<string,string>
)
row format delimited ','
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
分区表
用分区表来水平分散压力,将数据从物理上转移到和使用最频繁的用户更近的地方,以及实现其他目的,使用partitioned by关键字创建分区表。
特点:
- Hive中通常要对输入进行全盘扫描,来满足查询条件,这样的方式效率很低的,这时,可以通过创建很多的分区可以优化一些查询。
- 对表分区应该按照一下两种原则:
- 不应该导致产生太多的分区和文件夹目录。
- 每个目录下的文件应该足够大,应该是文件系统中块大小的若干倍。
- 一般对表分区是按事件或城市进行分区。
- 分区字段是一个虚拟字段,它不存放任何数据。
1
2
3
4
5
6
7
8
9
10
11# 创建分区表
create table test2(
name string,
age string,
sex string
)
partitioned by (work_city string)
row format delimited fields terminated by ',';
-- 静态插入
load data local inpath '本地数据地址' into table test2 partition(work_city='chengdu');
动态分区
1 | -- 打开动态分区功能 |
分桶表
目的是把一个表的颗粒划分的更细一些,提高查询效率和为join操作做数据准备,当join时,仅加载部分粪桶的数据到内存,避免内存溢出。所谓的分桶就是按照某个字段把它划分成几个部分。
1 | -- 开启分桶 |
内部表与外部表
- Hive中的表分为内部表和外部表;默认情况创建的是内部表,加上关键字
external后创建出来的表是外部表。 - 内部表外部表的区别
- 创建外部表需要加external关键字。
- 外部表不持有数据,而内部表对数据拥有管理权。
- 删除外部表时候,只是删除表的本身,数据并没有被删除,而删除外部表时,把表和数据一起删除,被删除的数据也不可以恢复。
- 内部表和外部表在加载数据时,如果从HDFS中加载将HDFS中的数据移动到Hive所管理的目录下。如果从本地加载,数据是被复制到Hive所管理的目录下。
1 | -- 创建内部表 |
加载数据
- 从本地加载数据
1
load data local inpath '本地数据路径' overwrite into table score;
- 从HDFS中加载数据到外部表
1
load data inpath 'HDFS数据路径' overwrite into table score2;
修改表
- 大多数的表属性都可以通过
alter table语句进行修改,这种操作会修改元数据,但不会修改数据本身。 - 重命名
1
alter table 原表名 rename to 新表名;
- 增加新字段
1
2
3
4alter table 表名 add columns(
新字段1 类型,
新字段2 类型
) - 修改字段的顺序
1
alter table 表名 change column 字段名1 字段名2 类型 after 字段名2;
删除表
- 删除字段
1
2-- ()括号里是需要保留的字段
alter table 表名 replace columns(字段1 类型,字段2 类型) - 删除表
1
drop table [if exists] 表名;
其它常用Hive操作
在其它数据库中用增、删、改、查操作,在Hive中,只是对数据的增加和查询操作。
- 从本地加载数据到Hive目录
1
load data local inpath '本地路径' [overwrite] into table 表;
- 从HDFS加载数据到Hive目录(数据加载到Hive目录后,原始数据将会被删除)
1
load data inpath 'HDFS路径' [overwrite] into table 表;
- 将查询结果追加到另一张表
1
insert into table 表1 select * from 表2;
- 将查询结果插入到另一张表并覆盖里面的内容
1
insert overwirte table 表1 select * from 表2;
- 通过查询结果创建一张新表(数据备份)
1
create table 表1 as select * from 表2;
- 从Hive中下载数据
1
hive -S -e 'select * from 表;' > localFIle
常用函数
| 函数 | 说明 |
|---|---|
| round(double d) | 四舍五入,保留整数 |
| round(double d, int n) | 四舍五入,保留n位置 |
| rand() | 随机数,范围0~1之间 |
| count(*) | 计算总行数,包含null |
| count(1) | 计算总行数,不包含null |
| avg(col) | 求平均数 |
| min(col) | 求最小 |
| max(col) | 求最大 |
| var_pop(col) | 求方差 |
| stddev_pop(col) | 求标准偏差 |
| concat(string s1, string s2, …) | 将s1、s2、…拼接 |
| length(string s) | 计算字符串长度 |
| lower(string s) | 将字符串全部转换成小写字母 |
| upper(string s) | 将字符串全部转换成大写字母 |
| ltrim(string s) | 去掉左边空格 |
| rtrim(string s) | 去掉右边空格 |
| trim(string s) | 去掉前后全部空格 |
| regexp_extract(string s, string regex, string replacement) | 替换某个字符,将字符串s中符合regex条件的部分替换成replacement |
| translate(string s, string from, string to) | 将s字段中from字符替换成to |
| reverse(string s) | 翻转字符串 |
| substr(string s, int i, int j) | 截取s字符串,从i开始,截取j位 |
常用操作
- limit语句:用于限制返回的行数
- 别名:一个复杂的查询结果通常需要给它指定新的名称,也就是别名。别名是在
as关键字后面加上新的名称即可。 - 判断语句:case … when … then end;
1
2
3
4
5
6
7
8
9-- 例子
select name, salary,
case
when salary >=5000 then '高'
when salary<5000 and salary >3000 then '一般'
when salary<3000 and salary >0 then '低'
else '异常'
end as new_salary
from 表名; - where 语句 :用于过滤条件,需要与select结合使用,可以查到符合过滤条件的记录。
- like 语句 :用于模糊查询,可以指定特地那个的子字符串在字符串内的任何位置进行匹配。
1
select * from 表名 where city like '%字符串%'
- rlike 语句 :是hive中特定的指定匹配条件
1
select * from 表名 where 字段名 rlike '.*(字符|字符).*';
- group by 语句:分组,通常与聚合函数一起使用,按照一个或者多个字段对结果进行分组,然后对每个组执行聚合操作。
group by后面可以跟having子句,having子句允许用户通过一个简单的语法完成原本需要通过子查询才能对group by语句产生的分组进行条件过滤任务。1
2
3
4
5select year(ymd), avg(price_close)
form stocks
where exchange='zzz' and symbol =='ddd'
group by year(ymd)
having avg(price_close) > 50.0; - join 语句 :Hive中支持通常的sql join语句,但只支持等值连接。
join是用于两张表或多张表的连接,只要两个表中都存在与连接标准相匹配的数据才会被保留下来。1
select t1.a, t2.b from 表1 t1 join 表2 t2 on t1.id=t2.id;
- order by 语句 :它与其它的sql中的定义是一样的,其会对查询结果集执行一个全局排序,这也就是说会有一个所有数据都通过一个reeduce进行处理的过程,对于大数据集这个过程可能会消耗太过漫长的时间来执行。
- sort by 语句 :Hive增加了一个可供选择的方式,
sort by其只会 在每个reduce中对数据进行排序,也就是执行一个局部排序过程,这可以保证每个reduce的输出数据都是有序的,这样可以提高后面进行全局排序的效率。 - Union all和union作用是可以将2个或多个表进行合并,每个union子查询都必需具有相同的字段。Union all和union区别是:
- Union :对两个结果集进行并集操作,不包括重复行,同时进行规则的排序
- Union all :对连个结果集进行并集操作,包括重复行,同时进行规则的排序
- 视图 :传统的嵌套形式可以满足下面的查询,当查询变得长或复杂的时候,传统嵌套方式就显的繁琐复杂,这是可以通过使用视图将这个查询分割成多个小的、更可控的片段,可以降低这种复杂度。
1
2
3
4
5
6
7-- 传统形式
select t.name, t.sex t.a1, t.a2, t.a3, t.a4
from (select * from new_scroe where name like '马%') t where t.sex='女';
# 视图形式
create view tmp_select as select * from new_score where like '马%';
select t.name, t.sex, t.a1, t.a2, t.a3, t.a4 from tmp_select t where t.sex='女';



喜欢这篇文章的人也看了
评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果